
Status: available
Supervisors: Michael Reiter, Matthias Wödlinger
Why?
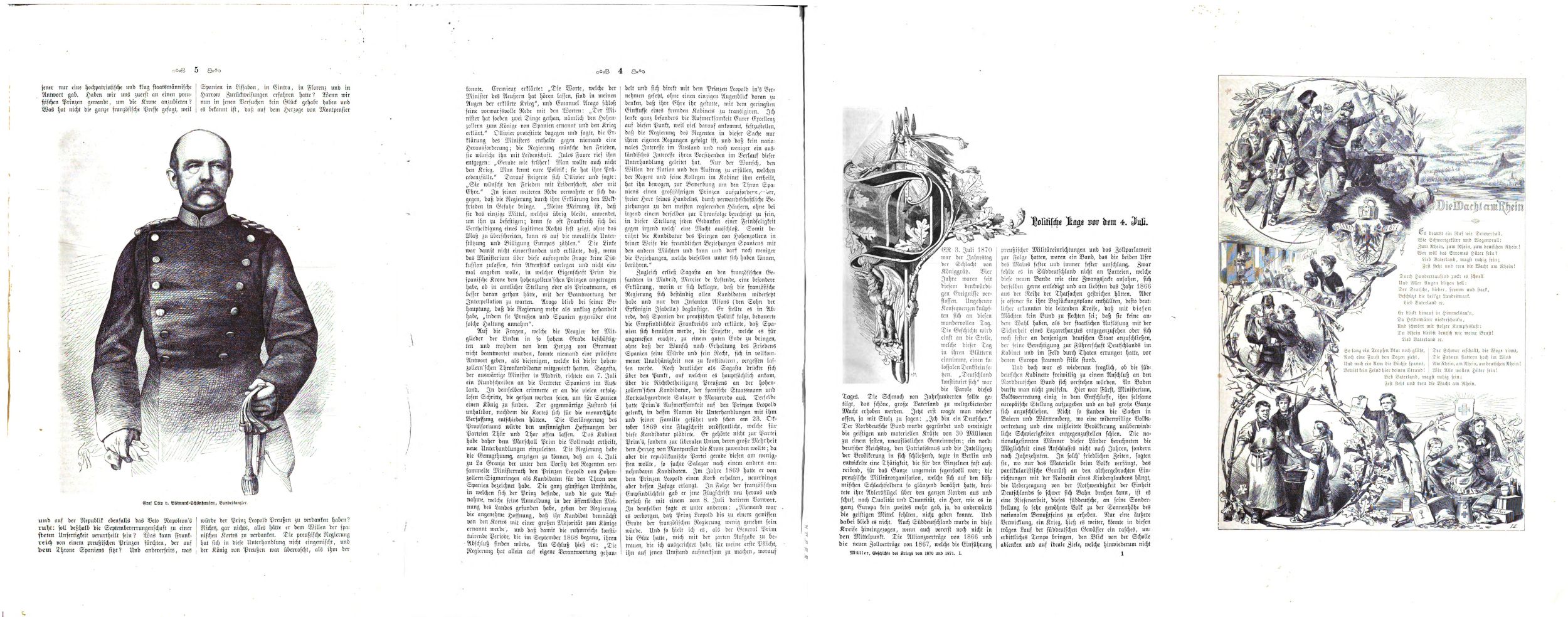
The target dataset is the enormous digitised collection of historical printed publications at Austrian National Library. In particular, Austrian Books Online (digitised over the last years in a large-scale cooperation with Google) and Austrian Newspapers Online from 16th to 19th century, which rank among the most important historical print collections worldwide and are of key relevance not only for research but also for the general public. In total the dataset contains over 200 million images of scanned document pages. The dataset is complemented by bibliographic metadata in RDF. Still hidden within these pages and not easily accessible are several millions of images of various kinds (illustrations, portraits, maps, scientific drawings, landscapes, stamps, logos, etc.), a highly valuable resource. Check out this link for some example pages from the dataset.
What?
The goal of this project is to process the full set of document page scans and extract pages that contain images. To do this you will train a neural network that automatically classifies document pages. The difficulties in this project lie in the large quantity of data that needs to be processed. You will need to develop a method that achieves a high accuracy while still running fast.
How?
- Literature Review – getting to know the methods
- Implementation & tinkering
- Evaluation
- Written Report/Thesis and final presentation
Helpful experience
- Python and numpy
- Basic understanding of machine learning and deep learning
- Machine Learning frameworks like PyTorch