

An Off-line Database for Writer Retrieval, Writer Identification and Word Spotting
 The CVL Database is a public database for writer retrieval, writer identification and word spotting. The database consists of 7 different handwritten texts (1 German and 6 Englisch Texts). In total 310 writers participated in the dataset. 27 of which wrote 7 texts and 283 writers had to write 5 texts. For each text a rgb color image (300 dpi) comprising the handwritten text and the printed text sample is available as well as a cropped version (only handwritten). An unique id identifies the writer, whereas the Bounding Boxes for each single word are stored in an XML file.
The CVL Database is a public database for writer retrieval, writer identification and word spotting. The database consists of 7 different handwritten texts (1 German and 6 Englisch Texts). In total 310 writers participated in the dataset. 27 of which wrote 7 texts and 283 writers had to write 5 texts. For each text a rgb color image (300 dpi) comprising the handwritten text and the printed text sample is available as well as a cropped version (only handwritten). An unique id identifies the writer, whereas the Bounding Boxes for each single word are stored in an XML file.
The CVL-database consists of images with cursively handwritten german and english texts which has been choosen from literary works. All pages have a unique writer id and the text number (separated by a dash) at the upper right corner, followed by the printed sample text. The text is placed between two horizontal separatores. Beneath the printed text individuals have been asked to write the text using a ruled undersheet to prevent curled text lines. The layout follows the style of the IAM database. The database was updated on 12/09/2013 since one writer ID (265/266) was wrong. The version number was changed to 1.1.
Samples of the following texts have been used:
- Edwin A. Abbot – Flatland: A Romance of Many Dimension (92 words).
- William Shakespeare – Mac Beth (49 words).
- Wikipedia – Mailüfterl (73 words, under CC Attribution-ShareALike License).
- Charles Darwin – Origin of Species (52 words).
- Johann Wolfgang von Goethe – Faust. Eine Tragödie (50 words).
- Oscar Wilde – The Picture of Dorian Gray (66 words).
- Edgar Allan Poe – The Fall of the House of Usher (78 words).
Download CVL-Database/XML Parser/GT-Viewer
![]()
Terms of Use and Citation Request
This database may be used for non-commercial research purpose only. If you publish material based on this database, we request you to include a reference to:
Florian Kleber, Stefan Fiel, Markus Diem and Robert Sablatnig, CVL-Database: An Off-line Database for Writer Retrieval, Writer Identification and Word Spotting, In Proc. of the 12th Int. Conference on Document Analysis and Recognition (ICDAR) 2013, pp. 560-564, 2013. pdf doi
GT-Viewer
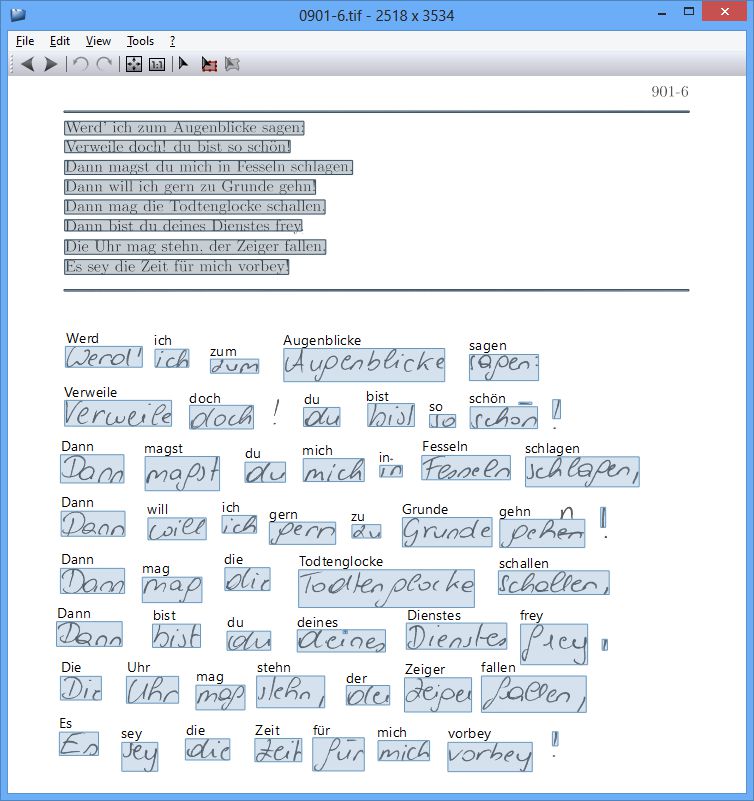 Labeled example page of the CVL Dataset (Text #5). It can be seen that all words of the text are surrounded by a bounding box (punctuation is not considered), which has been automatically calculated and manually checked by 2 individuals. The information is stored in a XML file. For a description on the XML file please take a look at the referenced paper. A XML-Parser (C++) is available to read the GT data.
Labeled example page of the CVL Dataset (Text #5). It can be seen that all words of the text are surrounded by a bounding box (punctuation is not considered), which has been automatically calculated and manually checked by 2 individuals. The information is stored in a XML file. For a description on the XML file please take a look at the referenced paper. A XML-Parser (C++) is available to read the GT data.
Contact
Robert Sablatnig, CVL, Vienna University of Technology:
e-mail: cvl-database@cvl.tuwien.ac.at

CVL Database is licensed under a Creative Commons Attribution-NonCommercial 3.0 Unported License.