
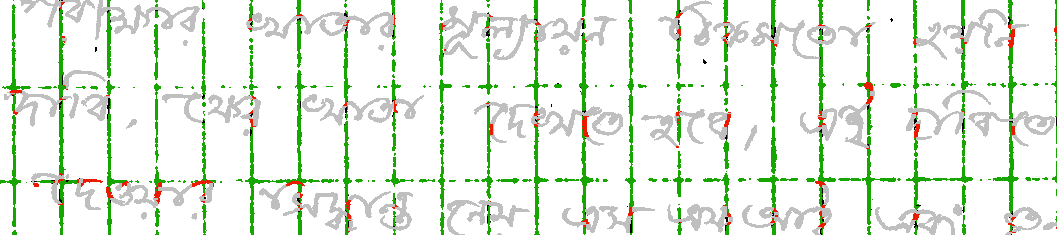
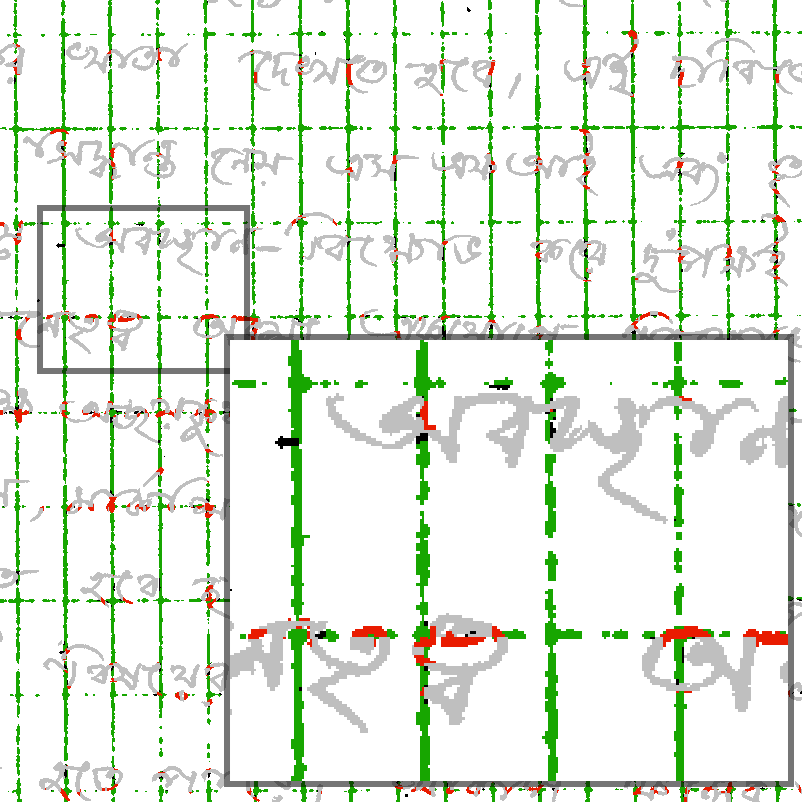
 The CVL ruling dataset was synthetically generated to allow for comparing different ruling removal methods. It is based on the ICDAR 2013 Handwriting Segmentation database [1]. It was generated by synthetically adding four different ruling images resulting in a total of 600 test images. The pixel values are:
The CVL ruling dataset was synthetically generated to allow for comparing different ruling removal methods. It is based on the ICDAR 2013 Handwriting Segmentation database [1]. It was generated by synthetically adding four different ruling images resulting in a total of 600 test images. The pixel values are:
- 255 background
- 155 ruling
- 100 text
- 0 ruling and text (overlaping)
For processing, a binary image must be generated which sets all pixels to 0 that are not 255. When evaluating, the line GT image can be found by setting all pixel having value 155 to one (e.g. linImg = img == 155). The text GT image can be extracted by setting all values below 155 to zero (e.g. txtImg = img < 155). Then, true positives (tp), false positives (fp) and false negatives (fn) are defined as:
- tp = result & linImg & !txtImg
- fp = result & !txtImg
- fn = !result & linImg & !txtImg
The database ships with a Matlab that gives evaluation results if all images are already processed.
Download
![]()
Contact
Robert Sablatnig, CVL, Vienna University of Technology:
e-mail: dir@cvl.tuwien.ac.at
References
[1] N. Stamatopoulos, B. Gatos, G. Louloudis, U. Pal and A. Alaei. ICDAR 2013 Handwriting Segmentation Contest. In Proceedings of the 12th International Conference on Document Analysis and Recognition, 2013, 1402-1406 doi
[2] Markus Diem, Florian Kleber and Robert Sablatnig. Ruling Analysis and Classification of Torn Documents. In ACM Symposium on Document Engineering. Colorado, USA, pages 63 – 72 2014.